编译框架学习笔记¶
Writted on 250217
Author: Jack_hui
从高级代码到机器语言¶
我们目前在各种ide上写的代码都是高级语言代码,比如Python、C、C++、Java等各种语言,这些语言机器无法直接识别并运行,因此需要一个媒介来进行转换。不同的语言需要不同的媒介,比如针对Python、JavaScript、shell的解释器,以及针对C、C++、Java等语言的编译器。并且根据媒介的不同,前者被称为解释型语言,后者被称为编译型语言。对于解释型语言的翻译过程,可类比现实生活中的同声传译,即解释器一行行的将高级语言代码翻译成机器二进制代码,交给机器运行;对于编译器,则是将高级语言代码全部翻译成机器二进制代码以后,再交给机器运行。由此不难看出解释型语言更加灵活,可根据硬件条件变化及时做出响应(JIT);而编译型语言编写的程序由于提前转化完毕,执行速度更快(AOT)。
编译过程¶
本次主要重点学习了编译相关的内容,接下来简要介绍一下编译过程:
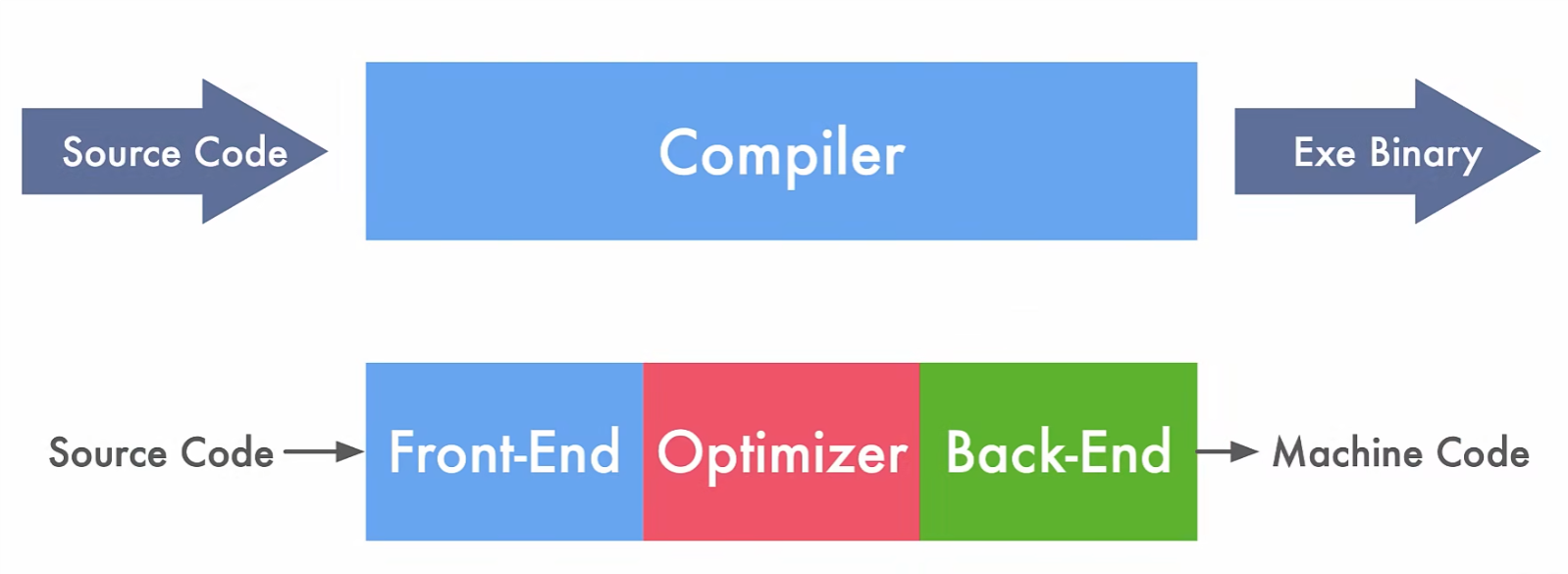 编译器大体可以分为三部分:
编译器大体可以分为三部分:编译前端、编译优化以及编译后端
编译前端¶
其中编译前端通常包括词法分析、语法分析、语义分析以及生成中间代码,
- 词法分析:将源代码分解成一个个独立的单元,每个单元都事先人为规定好的,示例如下
- 语法分析:接收词法分析的输出,生成抽象语法树(AST),只关心编写的高级代码形式上是否正确,而不关心逻辑是否存在问题。
- 语义分析:通过遍历抽象语法树,进一步检查编写的高级代码逻辑上是否存在问题。
- 中间代码:作为连接硬件与软件的媒介,软件工程师只需掌握前端高级语言,硬件工程师只需掌握相关硬件描述语言,然后两者共同学习中间代码的声明以及编写规则,便可高效完成开发。
编译优化¶
编译优化即对中间代码的优化,优化的方式有很多种,可根据个人按需进行,其中每种优化对应着一个pass,pass直观理解就是扫描源程序一遍,过程中解决特定的优化目标。整个编译优化过程通常需要多个pass,比如冗余代码删除,可用表达式分析等。
编译后端¶
编译后端主要将优化后的中间代码转化为目标机器代码,比如基于X86、ARM、MIPS、RISC-V等架构的二进制代码。
目前主流编译框架¶
Windows:Windows本身提供了MSVC编译工具链,集成在Visual Studio中。当然,也提供了MinGW以及MSY32等工具来模拟Unix/Linux操作环境,使用gcc进行编译。MacOs:MacOs早期使用的是GNU系列下的gcc等相关编译工具链,后来由于版本以及开源管理等问题转而开发了现在为人熟知的LLVM,其中clang就发挥着LLVM系列下编译前端的作用。Linux: 使用GNU系列下的GCC作为主要编译工具,其中gcc以及g++发挥着编译前端的作用,通常分别用来处理C和C++。
GCC¶
GCC是GNU编译工具链下的重要工具,配合Linux内核进行使用。整个工作流程如下所示:
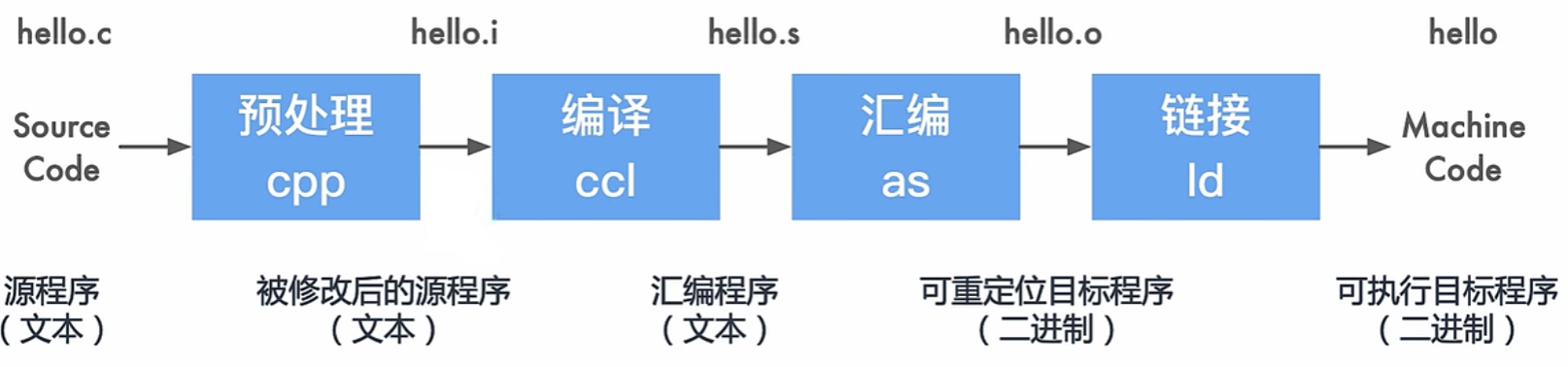
首先进行预编译,生成.i文件,主要引入头文件相关内容以及替换实现定义好的宏,然后将其转化成汇编代码,即.s文件,这里也可以看作是中间代码,紧接着根据中间代码生成可重定位的二进制文件(.o文件),最后根据文件之间的相互依赖关系进行链接,生成最终的可执行文件(.exe)。
LLVM¶
LLVM是苹果公司后来脱离GNU体系发展的成套编译工具链,其中日常接触比较多的clang就属于LLVM系列,发挥着编译前端的作用。这套体系整个编译流程如下所示:
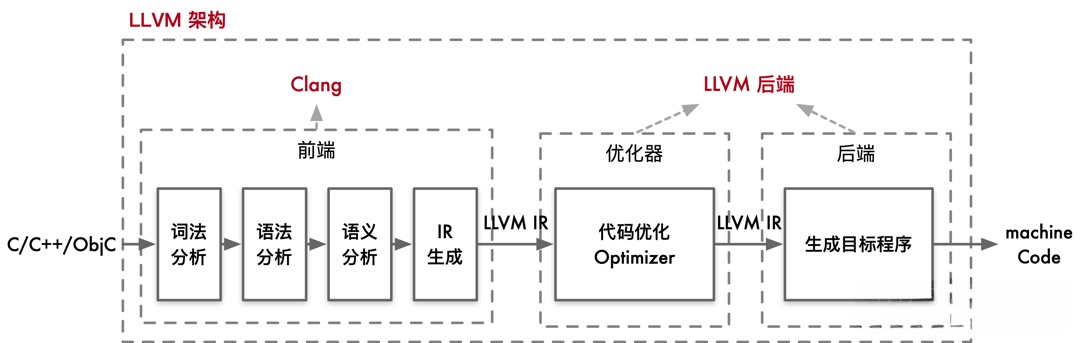
LLVM下编译过程的模块化更加明显,编译前端,编译优化以及编译后端被很好地划分出来。通过前端生成的.ll文件或者.bc文件(为中间代码的两种表示形式)以及相关pass进行优化,并将优化后产生的DAG图传递给编译后端生成相应的.s汇编文件,并在此基础之上生成二进制.o文件以及可执行文件.exe等。
两者的区别与联系¶
Example
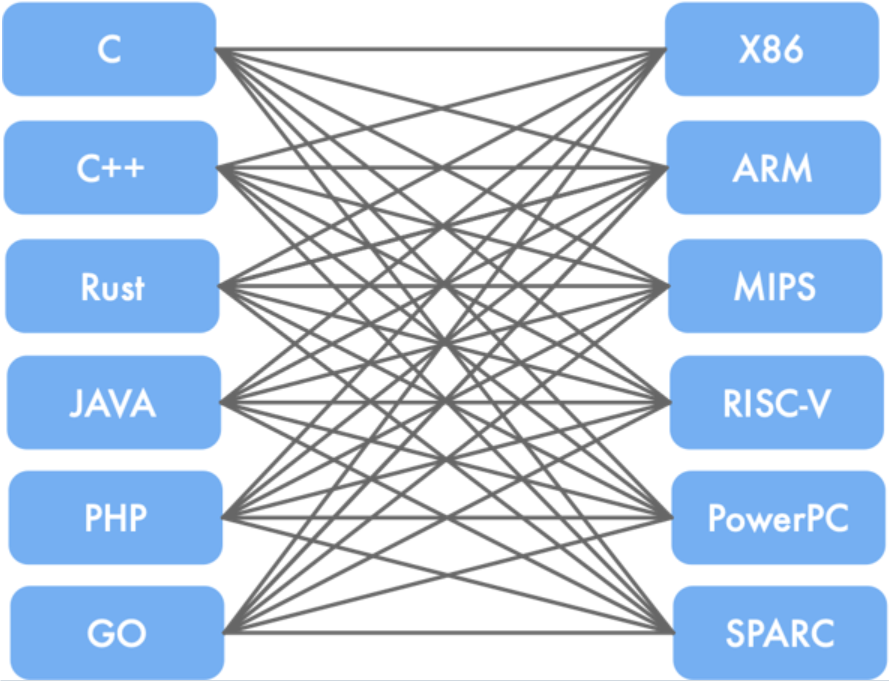 可以发现
可以发现GCC没有对编译过程的每个阶段作明显的区分,前后端耦合度过高,也就是前后端之间经常直接进行信息传递。因此添加新语言或新硬件平台需要修改大量代码,扩展性较差。不过由于发展历史悠久,经过长期优化,某些场景下生成代码的执行效率更高(如复杂数学运算、特定架构的深度优化等)。
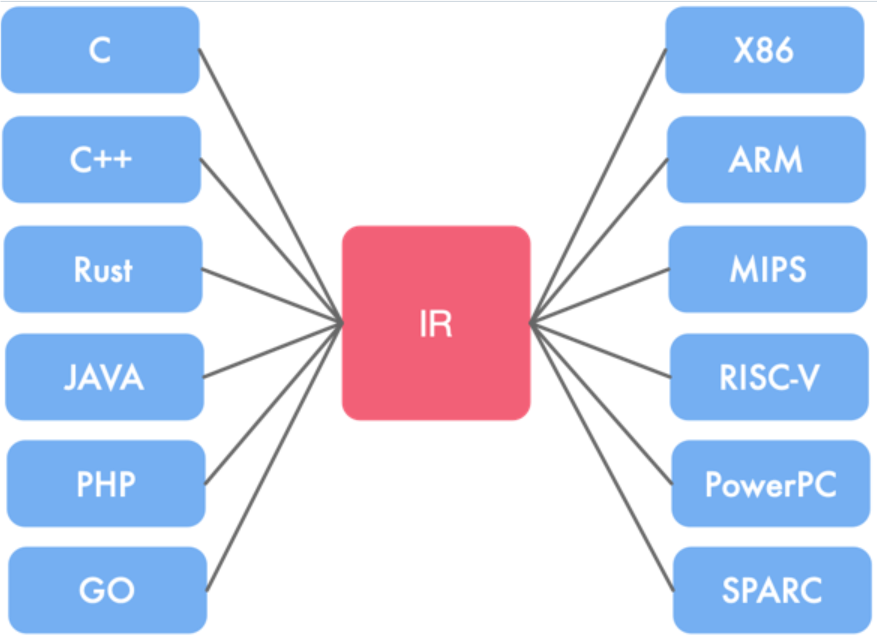
LLVM发展比GCC晚,有了前车之鉴以及相关经验,因此可以将视角更多地放在模块化上,其严格分离前端、优化器和后端,通过统一的中间表示LLVM IR连接。因此开发者可以独立开发新语言前端(如Clang用于C/C++)或硬件后端,复用优化器模块。
使用GCC以及clang编译源程序示例¶
这里使用简单的C程序作为待编译的源程序代码,示例代码如下:
GCC编译源程序¶
| Bash | |
|---|---|