自动微分概述¶
Writted on 250224
Author: Jack_hui
引言¶
在神经网络训练过程中,我们定义了损失函数,并且往往需要求其极值来使神经网络参数达到最优,比较著名的就是梯度下降法。而这一过程需要求损失函数对输入参数的导数,也就是微分。自动微分是目前AI框架下实现的核心技术,
实现方法¶
- 符号微分:通俗理解就是手工求导,根据已有的求导法则和链式法则,直接求损失函数对相应输入参数的导数,这种思路比较简单,但会带来一个问题,由于乘法以及除法等其他求导规则会让原有表达式规模翻倍,当神经网络层数以及参数量过多时,此时通过求导所得到的表达式规模往往是指数级的,大大增加运行时间以及存储所需空间。
-
数值微分:通过导数的定义:
\[ f'(x) = \lim_{\Delta x \to 0} \frac{f(x + \Delta x) - f(x)}{\Delta x} \]当\(\Delta x \to 0\)时,即求得对应点的微分。这种方法很容易实现,但要求\(\Delta x\)的值非常小,由于计算机的浮点表达能力有限,会产生截断误差以及舍入误差,再加上误差不断累积,这种方法性能并不是很好。
-
自动微分:自动微分的核心思想是利用中间变量以及链式法则,逐层微分,有点动态规划的思想在里面,接下来会详细介绍这个方法的两种模式。
自动微分的两种模式¶
这里用一个简单的例子进行说明,考虑如下函数:
对应计算图如下:
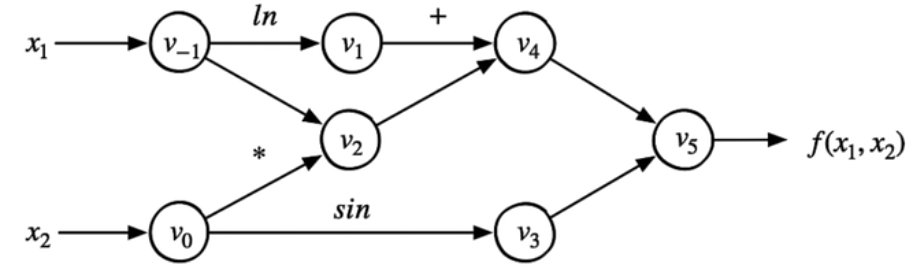
前向微分¶
要计算\(\frac{\partial f}{\partial x_1}\),从前往后依次计算:
\(a = \frac{\partial v_-1}{\partial x_1}\)
\(b = \frac{\partial v_1}{\partial x_1} = \frac{\partial v_1}{\partial v_-1}*a\)
\(c = \frac{\partial v_2}{\partial x_1} = \frac{\partial v_2}{\partial v_-1}*a\)
\(d = \frac{\partial v_4}{\partial x_1} = \frac{\partial v_4}{\partial v_1}*b+\frac{\partial v_4}{\partial v_2}*c\)
\(e = \frac{\partial v_5}{\partial x_1} = \frac{\partial v_5}{\partial v_4}*d\)
最后可以得到\(\frac{\partial f}{\partial x_1} = \frac{\partial f}{\partial v_5}*e\)
后向微分¶
也可以从后往前计算,具体过程如下
\(a = \frac{\partial f}{\partial v_5}\)
\(b = \frac{\partial f}{\partial v_4} = \frac{\partial v_5}{\partial v_4}*a\)
\(c = \frac{\partial f}{\partial v_3} = \frac{\partial v_5}{\partial v_3}*a\)
\(d = \frac{\partial f}{\partial v_1} = \frac{\partial v_4}{\partial v_1}*b\)
\(e = \frac{\partial f}{\partial v_2} = \frac{\partial v_4}{\partial v_2}*b\)
\(g = \frac{\partial f}{\partial v_0} = \frac{\partial v_3}{\partial v_0}*c\)
\(h = \frac{\partial f}{\partial v_-1} = \frac{\partial v_1}{\partial v_-1}*d+\frac{\partial v_2}{\partial v_-1}*e\)
\(i = \frac{\partial f}{\partial x_2} = \frac{\partial v_0}{\partial x_2}*g\)
\(j = \frac{\partial f}{\partial x_1} = \frac{\partial v_-1}{\partial x_2}*h\)
可以发现i和j即为需要求得的目标微分
总结¶
观察前向以及后向两种微分模式,不难看出:在前向微分过程中,通过一次前向微分,可以求得所有输出损失函数对指定输入参数的导数,即
\(\frac{\partial f_1}{\partial x_1}\)、\(\frac{\partial f_2}{\partial x_1}\)、...、\(\frac{\partial f_n}{\partial x_1}\)
而在后向过程中,通过一次后向微分,可以求得指定输出损失函数对所有输入参数的导数,即
\(\frac{\partial f_1}{\partial x_1}\)、\(\frac{\partial f_1}{\partial x_2}\)、...、\(\frac{\partial f_1}{\partial x_n}\)
可以发现,当输入参数量少于输出参数量时,使用前向微分更高效;而输入参数量大于输出参数量时,使用后向微分更高效。目前神经网络模型基本上都是输入远大于输出,因此这也是大部分AI框架训练时采用后向微分的原因